AI is not a buzzword. It’s not a phase that will go away after some time. It has become part and parcel of our day to day. In November 2024, three Google engineers, Julia Wiesinger, Patrick Marlow, and Vladimir Vuskovic, worked on a whitepaper titled “Agents”. The whitepaper first appeared on X (formerly Twitter) in the first week of January and AI developers have been busy discussing, digesting and even further expanding the discussions to include use cases that were not covered. I had a good and informative discussion about it with a very good friend, and we both agreed on one thing: Our jobs are safe…!
In this post, I will provide a concise summary of the paper and my reflections on the application of Agents, particularly in RAG applications.
What is a RAG Application?
RAG stands for Retrieval Augmented Generation. It is the process of optimising the output of a large language model, so it references an authoritative knowledge base outside of its training data sources before generating a response. The data cut-off date for gpt4 for example is April 2023. This implies that any query that is posed to ChatGPT requiring information from beyond the training data cut-off date, it will hallucinate and just outrightly say it has no idea what we are talking about.
So a RAG application uses user-provided data (usually stored as vectors) to provide the LLM with contexts order than its own training data. It allows developers to provide more useful, accurate and issue-targeted contexts and reduce the chances of hallucinations, which some LLMs, especially ChatGPT is known for,
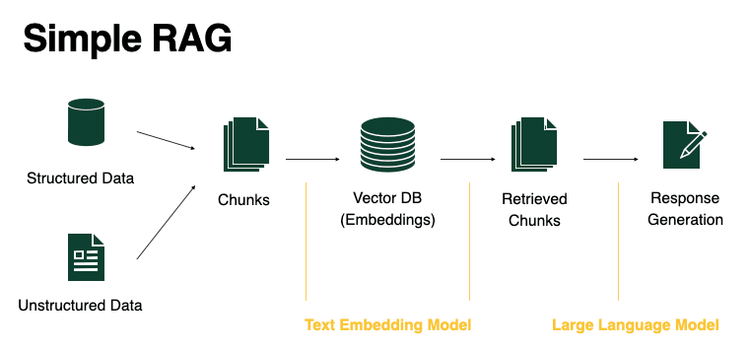
Source: BentoML
Additionally, we can picture a scenario where the documents of an establishment are too sensitive to share with public LLMs. This perhaps, is one of the best use cases of RAG applications, where a local or onsite LLM like Meta AI’s Llama is deployed and it consumes contexts directly from a local vector store.
What are Agents?
The authors have defined Agents as transformative entities, extending the capabilities of Large Language Models (LLMs) far beyond their original design. Agents enable a new level of autonomy, adaptability, and real-world functionality by integrating tools, reasoning frameworks, and data stores into LLMs. This post explores how agents are revolutionizing LLMs and driving the adoption of Retrieval-Augmented Generation (RAG) systems, making them indispensable for a wide range of applications.
Difference Between AI Models and AI Agents
AI models and AI agents represent two complementary but fundamentally different approaches to computational intelligence. While AI models like large language models (LLMs) excel at generating responses based on their training data, AI Agents take this capability a step further. Agents are designed to be proactive problem-solvers, equipped with the ability to interact with external systems, reason through complex scenarios, and dynamically adapt to changing contexts. With Elon Musk agreeing with AI experts that we have exhausted AI training data, Agents then provide a new cadre of engagement beyond learning and regurgitation of data.
In other words, while LLM models will generate near accurate data when provided with prompts and contexts, Agents will implicitly make decisions on your behalf without any need for prompts. See Agentic AI as AI that thinks, provides its own contexts and proceeds to make a decision on your behalf. For example, Agentic AI can learn your writing style, scan your mailboxes and respond to unanswered mails by learning about how you write and other factors.
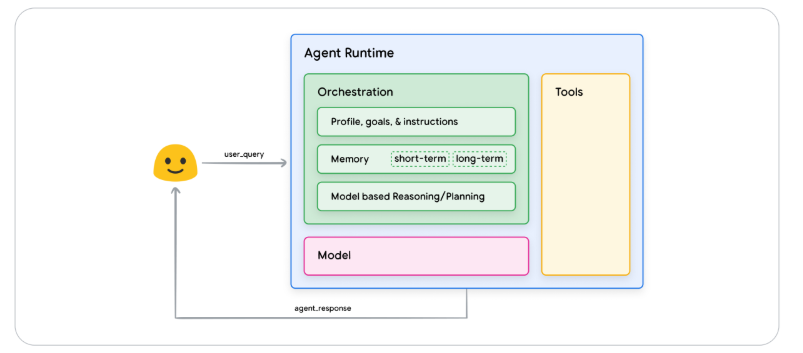
General Agents Architecture and Components (Source: Agents Whitepaper)
Components of Agentic AI
For Agents to be effective, it relies three important components. They are:
- The Model: This acts as the central decision-maker using frameworks like ReAct, Chain-of-Thought (CoT), and Tree-of-Thoughts (ToT). For example, ReAct is a prompt engineering framework that provides a thought process strategy for language models to Reason and take action on a user query, with or without in-context examples. ReAct prompting has shown to outperform several SOTA (state-of-the-art) baselines and improve human interoperability and trustworthiness of LLMs. CoT and ToT are other kinds of prompt engineering frameworks.
- Tools: Enable agents to access real-time external data or systems through APIs, enhancing capabilities beyond the model’s training data. Claude, Gemini, ChatGPT and other LLMs have shown excellence when it comes to generation of data. They however fall short when it comes to interaction with external systems. Supposing a developer needs to perform certain actions, based on the response of an LLM, say call an API, send an email, buy or sell a stock. This is where Agentic AI thrives, and more importantly, this is where Tools come to play. The paper highlighted three Tools utilized by Agents
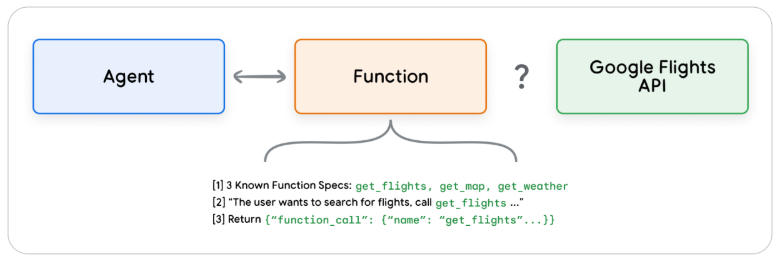
- Extensions: Let’s say a user queries an LLM with the input “book flight from Lagos to Abuja”. To respond to this query appropriately, the Agent needs to call external APIs like Google Flights API with the “from” and “to” parameters extracted from the user query. Supposing the user only queries “book flight to Abuja” without specifying a departure city, the above process will surely fail. A few lines of code and the right application of Agents empowered to call external API will solve this.
- Functions: Like Extensions, Functions are also part of the Tools toolbox that helps in supercharging AI powered applications. Software development or coding is normally an amalgamation of several pieces of functions, all working in perfect harmony. The developers write functions that performs different tasks and these functions are called when the need for them arises. Now in Agentic AI, the developer is replaced with the LLM. The LLM generates the parameterized or non-parametrized functions when they are needed and executed on the client side…All on the fly…!
- Data Stores: Lets imagine an trained on a vast amount of books. Unlike a typical library that constantly receives new volumes, books and other materials, this LLM does not. This will pose a challenge in a fast paced, ever changing world where new information is produced at the speed of thought. Data Stores ensure that the LLM, through the RAG, is equipped with more dynamic and accurate data to keep it up to date and it ensures that an LLM’s responses remain grounded in factuality
and relevant. 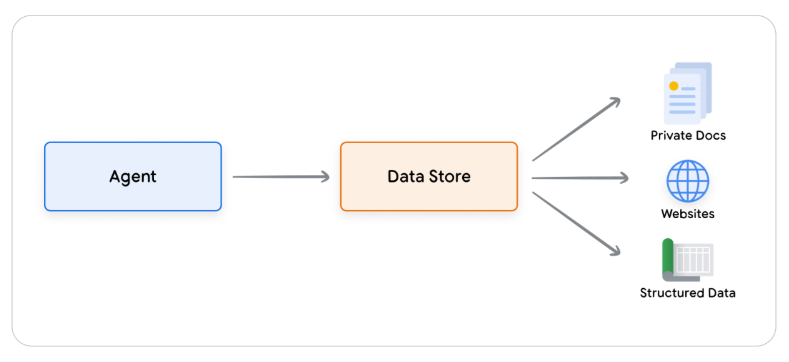 .
.
- Orchestration Layer: Governs how agents process inputs, make decisions, and execute tasks until goals are met.
Summary
Generative AI agents represent a transformative approach to artificial intelligence, extending the capabilities of language models through advanced cognitive architectures. These agents are designed to autonomously interact with external systems, access real-time information, and execute complex tasks beyond the known traditional limitations of LLMs
The core of an agent’s functionality lies in its orchestration layer, which enables advanced reasoning techniques like ReAct, Chain-of-Thought, and Tree-of-Thoughts. This layer facilitates intelligent decision-making, allowing agents to process information, reason, and generate informed responses.
Agents leverage three critical components: tools, reasoning frameworks, and data access mechanisms. Extensions connect agents to external APIs, functions provide granular control for developers, and data stores enable access to structured and unstructured information. This multi-faceted approach empowers agents to transcend the constraints of their foundational language models.
So as a developer not writing AI yet, your job might not be safe. Let this post be the sign from heaven for you to get started today…!